
Design a Collaborative Document Editor like Google Docs | Google PM Interview
Technical Product Questions for System Design: Follow step by step guide on how to answer system design questions in a PM Interview


You’re sitting across from your interviewer at a top tech company. The behavioral questions went well. You nailed the product design question. Then they lean forward and ask:
“Design a collaborative document editor like Google Docs with real-time sync and conflict resolution.”
Your mind races:
“Real-time sync?
Conflict resolution?
Where do I even start?”
This moment separates candidates who can handle complex technical questions from those who can’t.
“Design Collaborative Document Editor” is one of the the most challenging system design questions in PM interviews. It tests multiple dimensions simultaneously:
✅ Real-time systems understanding
✅ Conflict resolution approach
✅ Product prioritization
✅ Scale considerations
✅ Technical-product balance
What you’ll learn in this guide:
Complete S.P.E.C.T.S. framework walkthrough for this specific question
Deep dive on conflict resolution (OT vs CRDTs)
How to prioritize features for collaborative editing MVP
Evolution path from simple to scaled architecture
By the end, you’ll have a systematic approach to answer not just “Design Google Docs” but any real-time collaboration system design question.
The Hidden Challenge: Conflict Resolution
Most candidates describe components and data flows but completely skip the hardest technical problem:
→ What happens when two users edit the same position simultaneously?
Consider this scenario:
Document contains: “The cat”
User A types “ sat” at position 7
User B types “big “ at position 4 (simultaneously)
What’s the final result? How do you ensure both users see the same thing?
→ If you don’t address this explicitly, you’ve missed the core technical challenge.
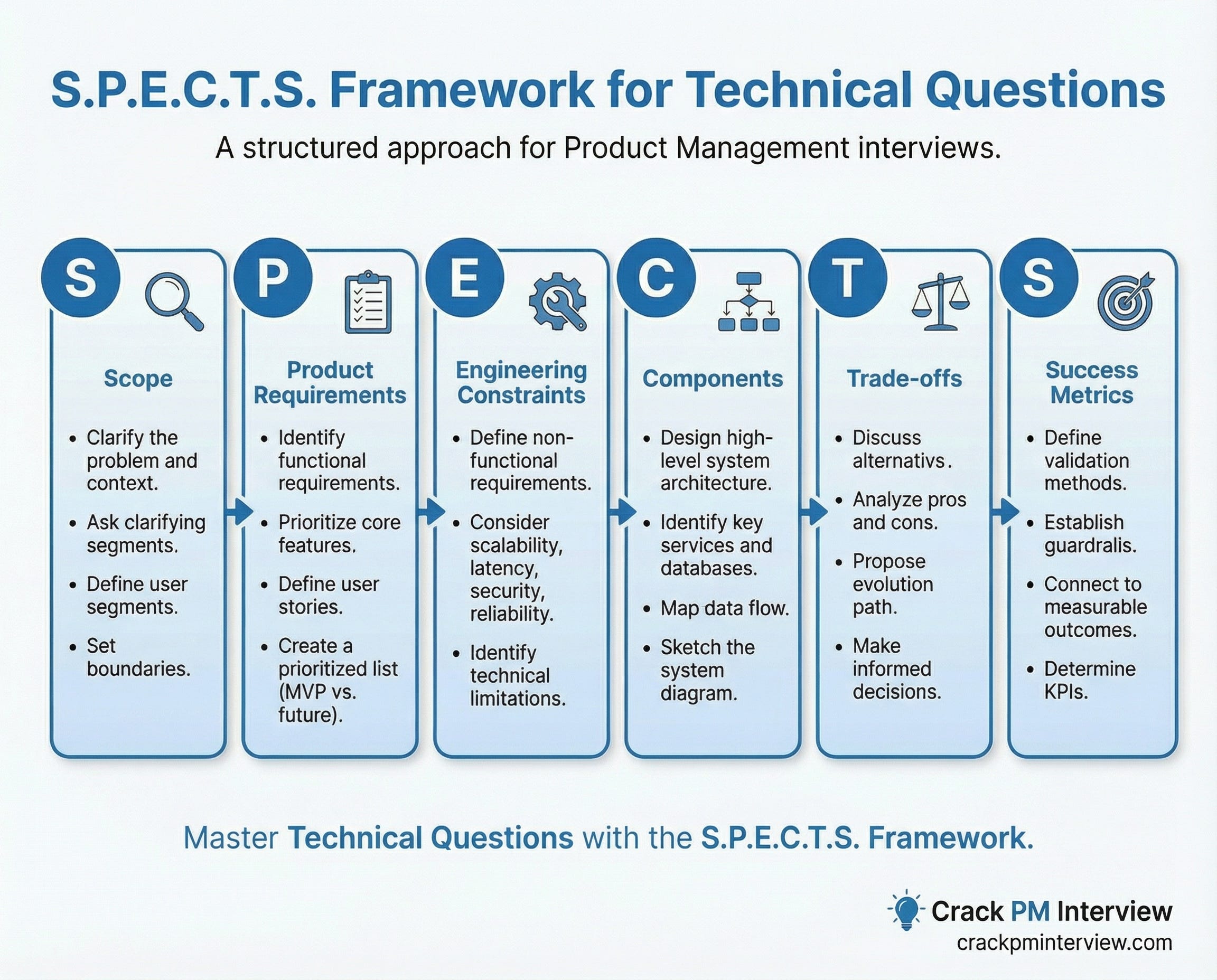
How to Answer System Design Questions?
Here’s a proven a repeatable framework that works perfectly well for system design questions and, in fact, for any technical question thrown at you.
Use the below S.P.E.C.T.S. Framework:
S - Scope - Clarify the problem and context.
P - Product Requirements - Identify and prioritize functional requirements.
E - Engineering Constraints - Define non-functional requirements.
C - Components - Design high-level system architecture.
T - Trade-offs - Discuss alternatives and evolution path.
S - Success Metrics - Define validation, guardrails and connect everything to measurable outcomes.
Now, let’s dive in and answer this question.
Step 1: Scope - Clarify the Problem and Context
Goal: Ensure you’re solving the right problem before diving into solutions.
Start by asking clarifying questions:
Users & Scale:
“How many concurrent editors per document are we designing for? 2-10 or 100+?”
“What’s the total user base? Thousands or millions?”
“Who are the primary users? Students, professionals, enterprises?”
Platform & Geography:
“Web-only initially or mobile too?”
“Single region or global deployment?”
“What’s the typical document size?”
Feature Scope:
“Text editing only or rich media like images and tables?”
“Is real-time sync mandatory or can we do periodic sync?”
“Is offline editing required in MVP?”
“Version history needed initially?”
Timeline:
“Are we building an MVP in 3 months or enterprise-grade in 12 months?”
Interviewer’s likely response:
“Focus on web-first, real-time text editing for 2-10 concurrent users. Assume 100K total users, documents averaging 10K characters. Offline can come later. Real-time sync is mandatory. 6-month MVP timeline.”
Now restate the problem:
Keep reading with a 7-day free trial
Subscribe to Crack PM Interview to keep reading this post and get 7 days of free access to the full post archives.