
How to Answer AI Product Evaluation and Metrics Questions | 2026 AI PM Interview Guide
Step-by-step guide to answering AI Evaluation & Metrics questions using the EVAL-AI framework, with AI-specific adaptations | By Crack PM Interview | crackpminterview.com



Picture this. You are thirty minutes into a PM interview at a company that ships AI products. The interview has gone well. You have been clear, structured, confident. Then the interviewer asks:
→ “How would you measure the success of our new AI writing assistant?”
You know this one. You have answered product metrics questions before. So you say:
→ “I would track daily active users, week-over-week retention, and NPS.”
You feel good about it. The answer is clean and structured.
The interviewer nods slowly. “Okay. And how would you know if the AI itself is performing well?”
You pause. “I suppose... accuracy?”
“How would you measure accuracy?”
Another pause. Longer this time.
That pause is what this article is written to eliminate.
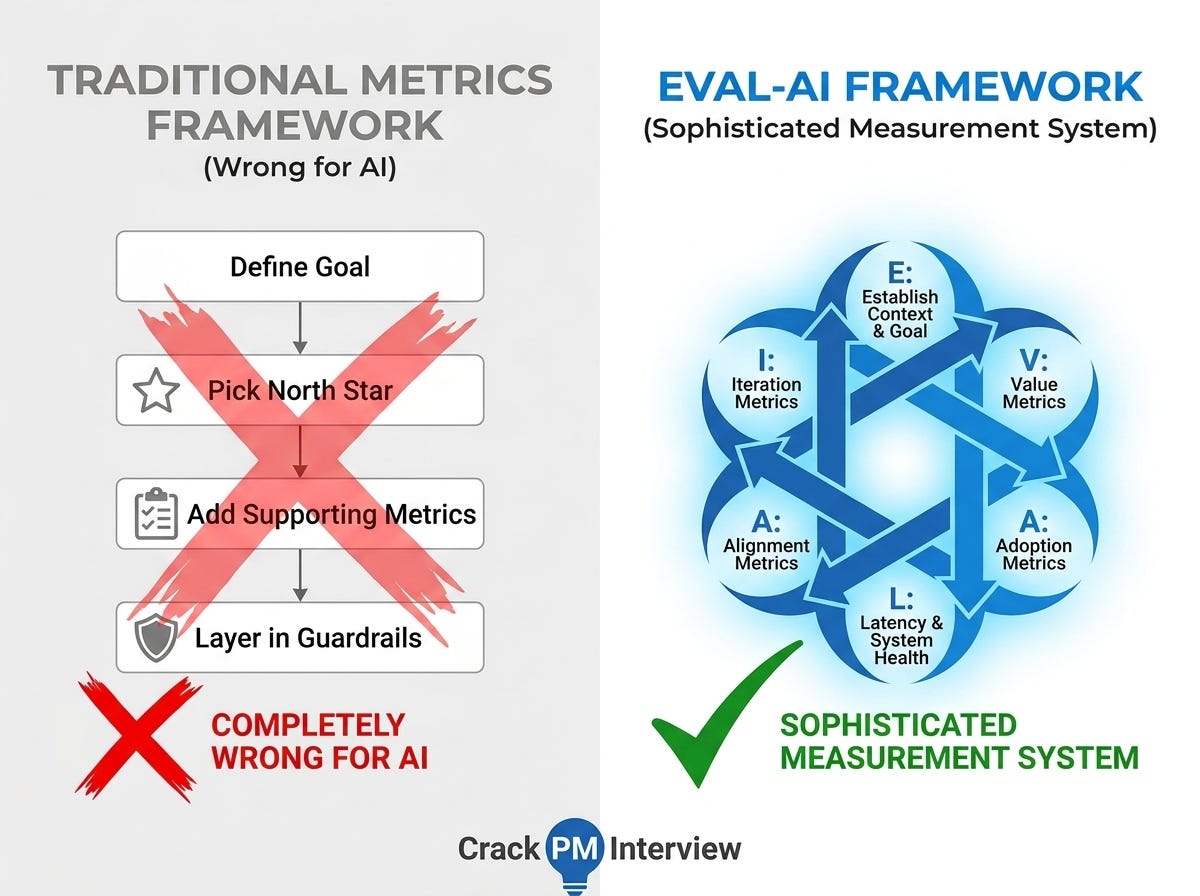
Most candidates who walk into AI PM interviews have answered metrics questions before - and that prior experience is exactly what gets them into trouble. They pattern-match to the traditional metrics framework they know: define the goal, pick a north star, add supporting metrics, layer in guardrails. Clean. Structured. Completely wrong for AI products.
AI products fail differently. They fail silently, probabilistically, and in ways that standard product dashboards will never surface. A model can degrade over weeks without throwing a single error. A user can feel frustrated by an AI response that is technically correct. An output can pass every automated check and still erode user trust over time.
The interviewer is not asking for a metrics list. They are asking whether you understand how AI products succeed and fail - and whether you can build a measurement system sophisticated enough to catch both.
This article teaches you how to do exactly that.
You will learn the EVAL-AI framework: a six-layer structure for answering any AI evaluation and metrics question, in any interview, for any product.
You will see it examples in action applying to GitHub Copilot.
You will learn the five most expensive mistakes candidates make on this question type.
And by the end, you will have twelve practice questions to apply the framework yourself.
BONUS: Mindmap for EVAL-AI Framework to Answer AI Evaluation and Metrics Questions
👉 Find full AI PM interview guide here
Product Sense is the single most skill that will differentiate you from others. Read below to learn Product Sense.
Table of Contents
What Interviewers Are Actually Testing?
Before you learn the framework, understand what the interviewer is reading from your answer. They’re not checking whether you know the right metrics. They’re evaluating you across five dimensions simultaneously.

Now, let’s jump to answering this question using EVAL-AI framework
Introducing EVAL-AI Framework to Answer AI Product Metrics Questions
EVAL-AI is a structured approach to answering any AI evaluation and metrics question. It covers six layers in sequence, each measuring something the others can’t.
Here’s the full framework at a glance:

Throughout this guide, I’ll walk through each step with a running example: “How would you measure the success of GitHub Copilot?” - one of the most commonly asked AI metrics questions.
Let’ dive deeper now.
Step 1: E - Establish Context and Goal
The single most common mistake in AI metrics interviews is jumping to metrics before establishing context. The result is a list of numbers that could apply to almost any product and signals nothing about your understanding of this specific AI product.
Before you name a single metric, establish three things.
What the AI product does, and what role AI specifically plays.
Not just “it’s a writing tool” - but “it uses a large language model to generate draft content from a user prompt, which means output quality is probabilistic and varies by prompt quality, domain, and model version.”
The more specific you are about the AI’s role, the more credible will be everything that follows.
What specifically you’re being asked to measure.
Launch success? Ongoing quality? A regression investigation? A head-to-head model comparison? The metric stack for measuring a new product launch differs significantly from the metric stack for diagnosing a quality regression.
Clarifying this early prevents you from building the wrong framework.
What “good” looks like for this product - and what failure looks like.
This is the move most candidates skip, and it’s the one that separates strong answers from great ones.
Name the failure mode before you name the metrics. An AI writing assistant fails when it sounds generic. An AI coding assistant fails when it suggests deprecated or insecure code. An AI customer support bot fails when it confidently gives a wrong answer. Naming the failure mode ensures your metrics are actually diagnostic of the thing that matters, not just measurable.
💡 Interview Tip:
Try opening with: “Before I name metrics, let me make sure I understand what failure looks like for this product.”
This single sentence signals AI PM depth before you’ve said anything else. It tells the interviewer you’re not about to read them a list - you’re about to build a diagnostic framework.
Example in Action for Step 1: GitHub Copilot
“Copilot is an AI code completion and generation tool powered by a large language model, integrated directly into the developer’s IDE. The AI’s role here is central - it watches what the developer is writing and proactively suggests completions, function bodies, tests, and documentation in real time. I’m assuming we’re measuring ongoing product success, not a specific launch or model comparison.
Before I name metrics, let me name the failure modes.
Copilot fails when it suggests deprecated APIs that a developer accepts without noticing - the suggestion looks correct but introduces security risk.
It fails when suggestions are so generic that editing them takes longer than writing from scratch.
It fails when latency is unpredictable enough that developers can’t build it into their flow.
And at a business level, it fails when developers don’t come back after early sessions because those sessions didn’t build enough trust.
Those failure modes are what my metric stack needs to catch.”
Step 2: V - Value Metrics (AI Output Quality Layer)
This is the layer most candidates skip entirely, and it’s the layer that most directly signals AI PM depth.
Value metrics measure the quality of the AI’s outputs directly - independent of whether users are engaging with them, whether business metrics are moving, or whether the system is running fast. These are the metrics that tell you whether the AI is actually doing what it’s supposed to do.
Accuracy and Correctness Metrics
Task accuracy: On a defined benchmark dataset, what percentage of tasks does the model complete correctly?
Measurement method: benchmark evaluation suite run on a representative sample of real-world task types.
Factual correctness rate: For outputs that make factual claims, what percentage are accurate?
Measurement method: human reviewers spot-check against verified sources, or an automated fact-checking pipeline cross-references outputs against a trusted knowledge base.
Hallucination rate: How often does the model generate confident but false or fabricated information?
Measurement method: LLM-as-a-judge evaluation with a rubric that distinguishes intrinsic hallucination (contradicting provided context), extrinsic hallucination (introducing unsupported facts), and fabrication (inventing entirely false claims). Human review of a calibration sample keeps the automated judge aligned.
Precision and recall: For classification or retrieval tasks, what’s the balance between false positives and false negatives? The right balance depends on which error is more costly for your use case.
Measurement method: benchmark dataset with labeled ground truth.
Quality and Relevance Metrics
Relevance score: Does the AI output actually address what the user asked?
Measurement method: LLM-as-a-judge on sampled outputs, calibrated against human reviewer scores.
Coherence score: Is the output logically consistent and well-structured?
Measurement method: automated judge or human evaluation rubric.
Domain-specific quality: This is where the most important V-layer metrics often live. For a coding assistant, it’s code compilation rate and security vulnerability rate. For a legal tool, it’s citation accuracy to real cases. For a medical tool, it’s clinical soundness. These aren’t generic quality scores - they’re the metrics that define what “correct” means for your specific product.
Evaluation Method Selection
Naming a value metric without naming how you’d measure it is an incomplete answer. Here’s how to reason through the trade-offs:

In practice, strong AI PMs layer these methods.
Use benchmark datasets for fast regression detection after each model update.
Use LLM-as-a-judge for scaled automated scoring.
Use human evaluation for calibration and for edge cases where subjective judgment matters most.
Use behavioral signals as the long-run ground truth check.
💡 Interview Tip:
“We’d measure hallucination rate” isn’t a metrics answer. It’s the beginning of one. Every metric you name needs a measurement method.
The candidates who stand out say: “For hallucination rate, I’d use LLM-as-a-judge with a rubric that separates intrinsic from extrinsic hallucination, calibrated monthly against human reviewer scores - because judge models can develop systematic blind spots if you don’t cross-check them.”
Example in Action for Step 2: GitHub Copilot
Keep reading with a 7-day free trial
Subscribe to Crack PM Interview to keep reading this post and get 7 days of free access to the full post archives.